Realtime Machine Learning
Started ; Updated Aug 08, 2023
In the Machine Learning Street Talk podcast’s episode on ‘Consciousness In The Chinese Room’, Francois Chollet’s criticism of the thought experiment struck me
of course the person executing the rules does not understand Chinese, that’s not where you would expect understanding to be located in the system. Understanding is an imagined property of the information processing system as a whole. Understanding is not in the instructions themselves it’s not in the processor that executes the instructions it’s in the functional dynamics of how the input information is being processed by the instructions.
He goes on to say that he believes the Chinese Room does not understand even if you are looking at the information processing system as a whole its because the book is static, or a crystallized skill, it can not adapt to changing circumstances
skill at a task is not sufficient to assert understanding of a task… intelligence is characterized by the ability to learn and adapt and efficiently pick up new skills from experience
If you understand what you’re doing then you can adapt what you’re doing when the world changes you can learn and adapt and improve and if you don’t understand what you’re doing then you’re stuck with a static skill and that’s really how you tell the difference between understanding and not understanding
This made me think of what used to be called “online learning” or real-time learning1.
So now I’m interested in doing some experiments with basic simulations, with neural networks that update their weights in real time and see where that leads. This is why I’m learning Rust incidentally.
Predator and Prey
The first experiment I’m going to try is a simple hunter-prey simulation like this
What Pezzza is doing here is to take a fixed architecture neural network (NN) with input from a visual field, lines that trace out from the agent and detect the presence of ether friend or foe, and fully connect them to two outputs: speed and direction.
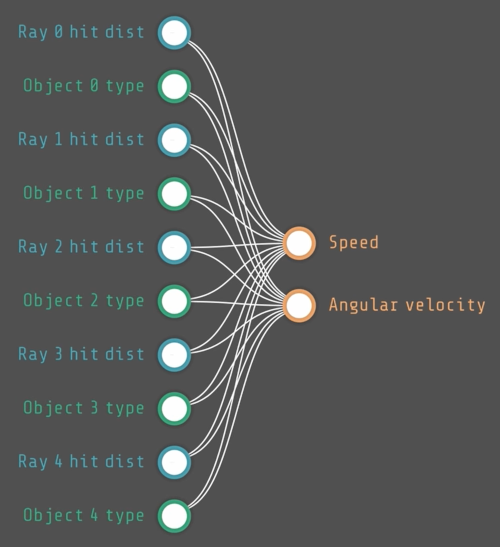
Then, instead of using backpropagation to tune the NN’s weights he is choosing them randomly and letting natural selection kill off the bad ones2 while the ones that survive long enough to multiply propagate. This allows him to train a NN without an objective function.
I want to take this basic setup and introduce real-time learning via backpropagation (BP). The problem with BP is that you need an objective function, which says how to update the weights. Its not obvious how to do this in this setup where the output is not the same as the objective function. This is where Reinforcement Learning traditionally.
There is also this very similar approch, in Rust and using the Bevy framework which is exactly where I wanted to go with it. AI learns to play retro game road fighter (Reinforcement learning)
In search of an objective
AlphaZero they seem to have trained a NN to rate chess board positions without the needing of an immediate objective, sort of.
From the paper Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
The Free Energy Principle seems to solve this problem by making the model try to predict the next sensor readings and minimising the difference between these predictions and the actual model state at the next time step. The model can also choose actions that it needs to predict the change in environment from. But how does it choose the action? Predicting the environment is key here but how does one steer the model to perform survival actions?
Predictive Models
Filip Piekniewski has this idea of predictive vision models which basically try to guess the next frame of video and there by model the world. One might look at this as the language modelling task of vision. He’s also suggesting adding online learning to this mix so the model trains and predicts at the same time, thus, according to Francois Chollet’s thesis would make it adaptive and thus conscious? And he’s got feedback from top back to bottom. He carries on about Associate Memory which is a type of NN (I need to look into)
to be continued…3
-
“Real-time” might be a better term as “online” implies the internet these days. ↩
-
Possibly he’s also mutating the offspring in order to get variation into the population. There might be crossover, the splicing of genes, by randomly selecting one of the other survivors to mate/share-genes with. ↩
-
This whole page is a work-in-progress and is just to document, and help me work through my ideas ↩